基于自动化发布流程多个可实现高效运维工具的实战应用分享
前言
曾几何时,生产部署是一件令运维头痛的事,充满着大量沟通和手动操作,可以说几乎占据着运维人员一半以上的工作时间。
在部署前期,架构师要把部署的架构和运维人员交代清楚,然后写成部署文档,运维人员要把这个文档中需要开墙的部分写成开墙需求提交网络管理人员,同时和系统管理人员,交代云上部署的虚拟机或云下部署的实体机,还需要申请上线的时间窗口。在部署期间,运维人员需要参照部署手册上的内容,一条条的实施部署,一个个的去启动应用,费时耗力,还很容易出错。一旦上线失败,就是责任事故,风险颇大。由于测试环境和生产环境的相对独立,有时一个微小的环境上的差异,会导致整个发布卡死甚至失败。
而现在,自动化发布完全取代了原先的发布,在发布前期,运维人员通过Terraform构建的完全一致的基础架构,用GitOps的流水线使得发布的代码库的唯一性,使用Jenkins使得持续集成持续发布CICD自动化,使用kubenetes使得测试环境和测试环境完全一致。而在CICD中还集成的单元测试、代码质量检测和代码安全检测等多种功能。可以说,现在的生产发布,几乎是一种水到渠成的工程。完全解决的过去发布的痛点。
而在经济大环境的影响下,很多企业都需要降本增效,Serverless正在被越来越多的引入到生产环境上来,很多其他平时的任务和作业适合于这种应用,甚至AWS在Database和Redis上相继推出的Serverless版,打破了业界的认知。
所以,目前在对于云上的发布的流程基本上是,Terraform部署基础架构 -> Jenkins类的CICD工具发布应用 -> 无服务化部署定时和事件触发的作业。
本文将从如何建设自动化发布流程的原理入手,介绍各种工具的用法及如何实现。希望对大家有所帮助。
1 整体设计与选型
1.1 设计
我们设计的目标是把,基础架构、应用部署、实时作业全部通过代码实现,实现完全自动化的目标。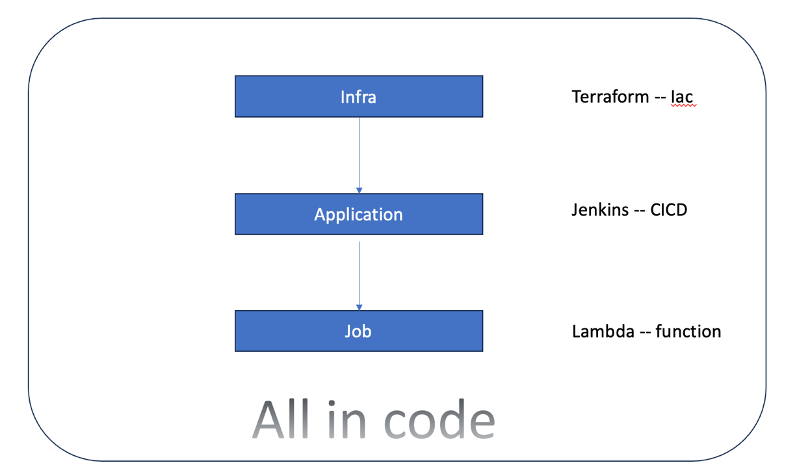
1.2 选型
1.2.1 Terraform
实际上已经是业界的一个标准,适用于各大公有云,适用性较广,可迁移性较强。在做适当修改后,在aws、tecent云也能部署。
1.2.2 Jenkins
不用我说,几乎每个开发都知道这个工具,我用过其他的CICD工具,比如ansible、tekton、argocd等,虽然其他工具也很灵活,但这同样也是缺点所在,太灵活导致配置太多了,如果要增加功能很多都需要客户化开发。而jenkins有大量的插件可供我们选择,可以实现低代码化。
1.2.3 Lambda
每一个公有云目前都有自己的功能函数,AWS中的Lambda,aliyun中的FC,这些可以实现无服务化。
下面,我将详述介绍这三个工具如何实现。
2 基础设施即代码
2.1 什么是基础设施即代码
基础设施即代码 是脚本自动执行基础结构和配置管理的一种方法。通过 相应的工具集,您可以对物理环境的详细信息进行抽象,从而使您能够专注于重要的代码。基础设施即代码可以解决许多问题。例如,简化配置管理,确保您的基础设施的预配方式与预配方式相同。它不仅仅是文档,也是任何现代软件开发的版本控制的重要组成部分。
2.2解决的问题
过去我记得公司里有个系统管理员,此人是和IDC机房沟通最为频繁的人,在公司的重要。机房里所有的布线、交换机的部署和服务器的配置,他都了如指掌。当时的应用部署在就是Vmware ESX 管理的虚拟机上,必须先行部署实体机。运维人员要部署应用前,必须和他充分沟通,他会驱车赶往机房,然后环境马上就可就绪了。
现在就无须这么麻烦了,除非是某些金融企业有自己的私有云需要打理,或某些企业有非常重要的应用必须私有化部署,一般的应用都部署在公有云上,而在公有云上的基础设施如果简单的话,完全可以手动部署。但是,公有云的架构复杂或有其他需求,如测试环境需求随时销毁重建时,或多账号部署需求环境完全一致时,我们就需要使用基础设施即代码,简称 Iac(infrastructure as code),顾名思义就是运行代码的方式在部署云上环境。
将基础设施部署为代码不仅意味着您可以将基础设施划分为模块化组件,并通过自动化以不同的方式组合它们,还可以通过自动配置服务器和操作系统来节省时间。开发人员每次创建应用时不必手动管理这些内容,从而节省时间。
2.3如何实现Iac
刚开始的时候,出现的是服务器自动化部署工具,就是如Cobbler、Ux-ignite等,这种类型工具是部署操作系统的,可以一键部署几十台甚至上百台的服务器,如图1。后来随着虚拟化的发展,ansible可以承担所有虚拟服务器的自动化搭建。但这些功能都无法实现网络的自动化部署,这是一个硬伤。 图一
图一
随着公有云的兴起,公有云的鼻祖Amazon 推出了一种全新的自动化部署理念,并将其实现在Cloudformation中,Cloudformation通过模版来描述所有AWS上的资源,如图二。可以轻松地为您的AWS环境创建模板。抛弃了之前的配置手册。但是缺点也很明显,首先就是代码无法转移到其他公司的云服务。 图二
图二
其次就是官方文档虽然比较完整,但是要花一些时间才能找到如何在代码中设置更好的设置。由于GUI设置的名称和代码中的设置并不总是匹配的,因此可能有必要在某种程度上猜测内容,比如上面GUI图对应的部分代码如图三,从中可以看到,对于图中S3对象存储GUI,并没有办法匹配代码中所有的配置信息。 图三
图三
也许是出于对以上缺点的考虑,terraform这个工具应运而生,这个工具有如下特点:
A. 声明式配置:Terraform使用一种声明式的编程语言来描述和定义所需的基础设施资源,这种声明式配置方式使得用户可以清晰地定义所需的资源和其属性,而不需要关心底层的具体实现细节。
B. 版本控制:Terraform支持将基础设施配置代码存储在版本控制系统中,如Git,这使得用户可以轻松地跟踪和管理基础设施的配置历史,以及回滚到之前的版本。
C. 多云和混合云支持:Terraform可以与多个云服务提供商集成,如AWS、Azure、Google Cloud等,用户可以使用Terraform来管理跨多个云平台的基础设施,实现资源的跨云迁移和复制。
D. 自动化部署和更新:Terraform通过执行计划来自动化基础设施的部署和更新过程,用户只需要编写一次基础设施配置代码,然后通过运行Terraform命令来创建、修改或删除资源。
E. 高可用性和可伸缩性:Terraform提供了一些高级功能,如故障恢复、负载均衡和自动扩展等,以确保基础设施的高可用性和可伸缩性。
F. 安全性和审计:Terraform支持对基础设施资源的访问控制和权限管理,以及对操作的审计日志记录,这有助于保护基础设施的安全性和合规性。
2.4 实际案例
该案例要构建一个项目,在阿里云上构建三个VPC,分别为 computer VPC,storage VPC,façade VPC,其中computer VPC中放置一个ACK的容器集群,storage VPC中放置Rds、Redis、Kafka,façade VPC中设置对外的ALB 、MSE、SNAT等。三个vpc间用 企联网CEN打通。
为了高可用,设置了三个可用区,三个可用区结合三个VPC 共设置九个vswitch。总体架构,如图四 图四
图四
Terraform 要对这个较为复杂的项目进行编码时,我们要设计一个总的项目目录 tf-project,其中包含environmenst和modules两个文件夹,在environment中包含dev、prod两个目录。这体现了我们希望设计的目标,那就是modules共用,但环境的terraform代码和各自的目录下,如图五
在dev和prod的main.tf中,写出总体的设计代码,如下所示,请注意其中locals并没有给出。
module "vpc_computer" {
source = "../../modules/vpc"
availability_zone = local.availability_zone
vpc_name = local.vpc_computer_name
vpc_cidr_block = local.vpc_computer_cidr_block
vsw_computer_node_cidrs = local.vsw_computer_node_cidrs
vsw_computer_terway_cidrs = local.vsw_computer_terway_cidrs
}
module "vpc_storage" {
source = "../../modules/vpc"
availability_zone = local.availability_zone
vpc_name = local.vpc_storage_name
vpc_cidr_block = local.vpc_storage_cidr_block
vsw_cidrs = local.vsw_storage_cidrs
}
module "vpc_facade" {
source = "../../modules/vpc"
availability_zone = local.availability_zone
vpc_name = local.vpc_facade_name
vpc_cidr_block = local.vpc_facade_cidr_block
vsw_cidrs = local.vsw_facade_cidrs
}
module "secgroup" {
source = "../../modules/secgroup"
vpc_id = module.vpc_facade.vpc_id
}
module "secdbgroup" {
source = "../../modules/secgroup"
vpc_id = module.vpc_storage.vpc_id
}
module "ecs" {
source = "../../modules/ecs"
region = local.region
instance_name = "bastion-01"
vsw_id = module.vpc_facade.vsws_id[0]
secgroup_id = module.secgroup.secgroup_id
}
module "ack" {
source = "../../modules/ack"
k8s_name_prefix = local.ack_name
availability_zone = local.availability_zone
ack_vswitch_id = module.vpc_computer.vsws_computer_id
ack_terway_vswitch_id = module.vpc_computer.vsws_computer_terway_id
ack_service_cidr = local.service_cidr
}
module "rds" {
source = "../../modules/rds"
instance_name = local.rds_instance_name
instance_type = local.rds_instance_type
instance_storage = local.rds_instance_storage
security_ips = local.rds_security_ips
vpc_id = module.vpc_storage.vpc_id
vswitch_id = module.vpc_storage.vsws_id
security_group_ids = module.secgroup.secdbgroup_id
availability_zone = local.availability_zone
db_name = local.rds_db_name
db_account = local.rds_db_account
db_passwd = local.rds_db_passwd
}
module "redis" {
source = "../../modules/redis"
db_instance_name = local.redis_instance_name
instance_class = local.redis_instance_class
security_ips = local.redis_security_ips
vswitch_id = module.vpc_storage.vsws_id
availability_zone = local.availability_zone
account_name = local.redis_account_name
account_passwd = local.redis_account_passwd
}
module "kafka" {
source = "../../modules/kafka"
name = local.kafka_name
partition_num = local.kafka_partition_num
disk_type = local.kafka_disk_type
disk_size = local.kafka_disk_size
io_max = local.kafka_io_max
spec_type = local.kafka_spec_type
vswitch_id = module.vpc_storage.vsws_id[1]
}
module "mse" {
source = "../../modules/mse"
gateway_name = local.mse_gateway_name
mse_spec = local.mse_spec
slb_spec = local.mse_slb_spec
vsw_id = module.vpc_computer.vsws_computer_terway_id
vpc_id = module.vpc_computer.vpc_id
}
module "certs" {
source = "../../modules/certification"
}
module "alb" {
source = "../../modules/alb"
alb_name = local.alb_gateway_name
load_balancer_edition = local.alb_edition
address_type = local.alb_address_type
vsw_id = module.vpc_facade.vsws_id
vpc_id = module.vpc_facade.vpc_id
acl_entries = local.alb_whitelist
acl_name = local.alb_acl_name
server_idip = module.pamse.mse_gateway_slb_ips[0]
cert_id = [module.pacerts.cert_douyin_id, module.pacerts.cert_apollo_id, module.pacerts.cert_vue_id]
}
module "cen" {
source = "../../modules/cen"
vpc_computer_id = module.vpc_computer.vpc_id
vpc_storage_id = module.vpc_storage.vpc_id
vpc_facade_id = module.vpc_facade.vpc_id
vsws_computer_id = module.vpc_computer.vsws_computer_id
vsws_computer_terway_id = module.vpc_computer.vsws_computer_terway_id
vsws_storage_id = module.vpc_storage.vsws_id
vsws_facade_id = module.vpc_facade.vsws_id
}
在modules文件夹中,是具体的每个组件实现的代码,如图六所示
可以看到,其中redis模块的main.tf中,包含了redis的配置、备份、账户信息。
而在prod中的main.tf 就可以对其调用。如图七所示 图七
图七
2.5 部署风险和应对
Terraform的部署支持完整的回退销毁,使用命令 terraform destroy 可以销毁所以使用terraform apply部署的基础组件,所以在生产上线前部署是非常安全的,一旦发现有部署不当,可以销毁、调整代码、重建。但是唯一的缺点就是不支持代码上的忽略,就是说,代码上有的组件必须部署不能忽略。这时,我们可以使用 terraform rm state <module> , 把不需要部署的组件从代码清单中去除。以后需要了再用 terraform import 导入配置。
3. 应用部署即代码
基础架构部署完后,接下来就要部署应用了。这也就是大家熟知的Devops 中的持续集成持续部署(CICD)。持续集成持续部署可以用很多工具来实现。
3.1 什么是持续集成持续部署
3.1.1持续集成:
A. 集成:就是在一起:代码commit是集成(代码在一起),
B. 编译是集成(逻辑在一起);
C. 部署是集成(部署包跟环境在一起),
D. 测试是集成(功能在一起),
E. 灰度是集成(系统在一起)不断的做集成和集成结果的修正,就是持续集成;
3.1.2持续交付:
A. 交付:就是将最终的产品发布到线上环境,给用户使用。
B. 持续交付描述的软件开发,是从原始需求识别到最终产品部署到生产环境这个过程中,需求以小批量形式在团队的各个角色间顺畅流动,能够以较短地周期完成需求的小粒度频繁交付。频繁的交付周期带来了 更迅速的对软件的反馈,并且在这个过程中,各个角色密切协作,相比于传统的瀑布式软件团队,更少浪费。
3.1.3 持续部署
A. 就是持续的将需求部署到目标环境上。
B. 持续交付的延伸就是持续部署
3.2 持续集成持续部署的工具
工具上大致分为2大类,服务器CICD工具和容器CICD工具
3.2.1 服务器CICD工具
就是以服务器上的应用部署为主的部署,主要工具是ansible+git,slatstack+git等。此类工具在很长一段时间内盛极一时。成为很多大公司的不二之选,Ansible还得到很大的发展,出现了Ansible Tower等图形化应用自动化部署工具,如图八 图八
图八
3.2.2 容器CICD工具
就是以kubenetes容器应用为主的部署,主要工具就是 Tiktok+ArgoCD,Jenkins等工具。此类工具是目前的主流,其中Tiktok+ArgoCD工具涉及到大量的配置和定制化的开发,使用较为不变,而Jenkins可以和groovy语句结合,并使用大量的plugins扩大起功能,所以在国内外使用非常广泛。下面对Jenkins在生产使用中的种种配置,一一介绍。
Jenkins可以实现参数化部署(Build with Parameter),这是最为常见的部署方式。在参数中,你可以定义环境、是否需要代码质量检测、版本号等诸多设置,如图九所示
Jenkins可以和gitlab、github、bitbucket等多种git工具结合,实现真正的GitOps,如图十 图十
图十
在生产上Jenkins所有部署都不在Jenkisn上设置,都依赖从git中传来的的Jenkinsfile文件,如图十一 图十一
图十一
3.3 实际案例
使用Jenkins+groovf 来实现CICD部署,在工作中,一般我会遇到2种CICD的方案,一是CI和CD融合,完全流程化。这是在标准化非常成熟的团队使用的方案,大致的意思就是,在这个团队中,开发、测试、运维都实现了标准化,一个工程从研发分支、单元测试、性能测试,不同环境的部署都有详细的定义,流程被不择不扣的执行。二是CI和CD分离,部分流程化,其中加入了人为决定的环节,比如要上线时,什么功能能上线,什么功能要缓一缓要开发主管来决定,而不是由质量测试部门来决定。三是CI和CD部分融合,不完全流程化,比如在测试环境实现CI和CD融合,而在生产环境实现分离。本案例所示是第三种方案。
下面是CI的Jenkinsfile的代码,使用ubuntu的agent,以下代码包括了checkout,update the image两个stage
@Library(['xxxJenkinsLibrary@2', 'xxxxJenkinsLibrary']) _
import java.text.SimpleDateFormat
import groovy.json.JsonOutput
node('ubuntu_java-11_docker-20') {
env.USER_EMAIL = "xxxx@xxxx.com"
env.USER = "xxxx"
env.TOKEN = "sonar-xx-xxx-token"
node('ubuntu_java-11_docker-20') {
env.USER_EMAIL = "xxxx@xxxx.com"
env.USER = "xxxx"
env.TOKEN = "sonar-xx-xxx-token"
env.SONAR_HOST_URL = "https://xxxx.tools.xxx.net/"
env.PROJECT_NAME = "xxxx.xxxx.java"
stage('check out') {
checkout scm
commitId = tools.git.getCommitId()
version = BUILD_NUMBER
def sdf = new SimpleDateFormat("yyyyMMddHHmmss")
env.COMPONENT=env.APP_NAME
env.COMPONENT_COMMIT=commitId
env.COMPONENT_VERSION=version
env.DateTime=sdf.format(new Date())
}
// set docker image name
if (["develop"].any{branch -> BRANCH_NAME.startsWith(branch)}) {
env.simplifiedBranchName='develop'
} else if (["release/", "release", "feature/", "bugfix/", "hotfix/", "function/"].any{branch -> BRANCH_NAME.startsWith(branch)}) {
env.simplifiedBranchName=BRANCH_NAME.toLowerCase().split('/')[0]
} else if (["PR-"].any{branch -> BRANCH_NAME.startsWith(branch)}) {
env.simplifiedBranchName='pull-request'
} else if (['master'].any{branch -> BRANCH_NAME.startsWith(branch)}) {
env.simplifiedBranchName='master'
} else {
env.simplifiedBranchName = ''
}
if (env.simplifiedBranchName != '') {
env.IMAGE_NAME = env.APP_NAME+"_"+env.simplifiedBranchName+":"+'-'+env.DateTime
}
if (["develop"].any{branch -> BRANCH_NAME.startsWith(branch)}) {
env.DEPLOY_ENV = 'development'
} else {
env.DEPLOY_ENV = ''
}
if (env.BRANCH_NAME == 'develop' || env.BRANCH_NAME.startsWith('function/') || env.BRANCH_NAME.startsWith('bugfix/') || env.BRANCH_NAME.startsWith('feature/') || env.BRANCH_NAME.startsWith('release/')) {
stage('Upload the image') {
println "OMNI_COMPONENT_COMMIT=${OMNI_COMPONENT_COMMIT}"
timeout(time: 30, unit: 'MINUTES') {
withCredentials([string(credentialsId: ARTIFACTORY_CREDENTIAL, variable: 'JFROG_KEY'),usernamePassword(credentialsId: ACR_DOCKER_CREDENTIAL, usernameVariable: 'ACR_DOCKER_USERNAME', passwordVariable: 'ACR_DOCKER_PASSWORD'),usernamePassword(credentialsId: ADI_DOCKER_CREDENTIAL, usernameVariable: 'ADI_DOCKER_USERNAME', passwordVariable: 'ADI_DOCKER_PASSWORD')
]) {
sh """
#!/bin/bash
set -x
envsubst '\\\\${JFROG_KEY}' < .mvn/settings.xml.template > .mvn/settings.xml
docker login ${ADI_HARBOR_ADDR} -u ${ADI_DOCKER_USERNAME} -p ${ADI_DOCKER_PASSWORD}
./mvnw clean package -Dmaven.test.skip=true -s .mvn/settings.xml -U
docker login ${ACR_HARBOR_ADDR} -u ${ACR_DOCKER_USERNAME} -p ${ACR_DOCKER_PASSWORD}
docker build -t ${ACR_HARBOR_ADDR}/${ACR_NAMESPACE}/${IMAGE_NAME} --build-arg OMNI_COMPONENT=${OMNI_COMPONENT} --build-arg OMNI_COMPONENT_VERSION=${OMNI_COMPONENT_VERSION} --build-arg OMNI_COMPONENT_COMMIT=${OMNI_COMPONENT_COMMIT} .
docker push ${ACR_HARBOR_ADDR}/${ACR_NAMESPACE}/${IMAGE_NAME}
docker rmi ${ACR_HARBOR_ADDR}/${ACR_NAMESPACE}/${IMAGE_NAME}
"""
}
}
}上传镜像后,如果是测试环境,需要去调动CD流水线,执行发布,代码如下
if (env.IMAGE_NAME != '' && env.DEPLOY_ENV != '') {
stage("Trigger Deployment") {
build job: env.DEPLOYMENT_PIPELINE,
parameters: [
string(name: 'IMAGE_NAME', value: env.IMAGE_NAME),
string(name: 'environment', value: env.DEPLOY_ENV),
string(name: 'APP_NAME',value: env.APP_NAME)
]
}
}
最后一个stage是send notification,对相关人员的通知
if (env.BRANCH_NAME == 'develop' || env.BRANCH_NAME.startsWith('release/')) {
stage('Send Notification') {
def body = "Build Completed: ${env.JOB_NAME} with buildnumber ${env.BUILD_NUMBER} (<${env.BUILD_URL}|Link)> its result was unclear"
if (currentBuild.currentResult == "SUCCESS") {
body = "Job: ${env.JOB_NAME}\\\\n Status: *SUCCESS*\\\\n Build Report: ${env.BUILD_URL}"
} else if (currentBuild.currentResult == "FAILURE") {
body = "Job: ${env.JOB_NAME}\\\\n Status: *FAILURE*\\\\n Error description: *Failed while building application* \\\\nBuild Report :${env.BUILD_URL}"
} else if (currentBuild.currentResult == "UNSTABLE") {
body = "Job: ${env.JOB_NAME}\\\\n Status: *UNSTABLE*\\\\n Error description: *Unstable while building application* \\\\nBuild Report :${env.BUILD_URL}"
}
timeout(time: 5, unit: 'MINUTES') {
emailext body: body,
subject: 'Deployment result',
to: "${USER_EMAIL}",
mimeType: 'text/html',
replyTo: "${USER_EMAIL}",
compressLog: true
}
}
}
}
在CD代码中,该项目使用kustomize实现对不同的环境,使用不同的配置进行部署,同样是如同terraform一样的目录结构,base目录是基本的配置,通常我们这里放的是开发环境的配置,而在overlay中的四个目录对应用于dev,staging、perprod,production四个环境,可以把对不同环境所对应的配置写在里面。如图十二所示 图十二
图十二
比如,如果在测试环境中,我要加入pod反亲和力,来实现离散的pod部署,如图十三所示 图十三
图十三
在CD流水线的jenkinsfile中,主要是对ack(k8s)cluster的部署,以下2个stage就是对k8s的部署和检查部署是否成功
stage("deploy deployment to k8s") {
// Deploy in k8s
if ( "${params.environment}" == 'production' ) {
// Request user input in order to deploy to Production
userProviderInput(message: "Deploy in Production",
timeout_message: "There is a pending ${APP_NAME} deployment of ${params.environment} in\\\\nPlease, confirm the deployment *<${env.RUN_DISPLAY_URL}|here>*",
)
withCredentials([file(credentialsId: 'svc-aliyun-ack-kubeconfig', variable: 'KUBECONFIG')]){
sh "chmod +w ${KUBECONFIG}"
sh "kubectl config use-context ${contexts[environment]}"
sh "kustomize build ./overlay/${environment} | kubectl apply -f - -n ${namespaces[environment]}"
}
}
else {
withCredentials([file(credentialsId: 'svc-aliyun-ack-kubeconfig', variable: 'KUBECONFIG')]){
sh "chmod +w ${KUBECONFIG}"
sh "kubectl config use-context ${contexts[environment]}"
sh "kustomize build ./overlay/${environment} | kubectl apply -f - -n ${namespaces[environment]}"
}
}
}
stage("Check deployment in k8s") {
withCredentials([
file(credentialsId: 'svc-aliyun-ack-kubeconfig', variable: 'KUBECONFIG')
]) {
sh "chmod +w ${KUBECONFIG}"
sh "kubectl config use-context ${contexts[environment]}"
for (String item: deployments[environment]) {
sh """
#!/bin/bash
kubectl rollout status deploy ${item} -n ${namespaces[environment]} &
wait
printf "The Deployment has been successful!"
"""
}
}
}
3.4部署风险和应对
在编写Jenkins pipeline时,一般由于疏忽和环境因素会遇到各种错误,但是一旦顺利跑通,再制定相应的操作SOP,那失败的风险就主要在于应用开发的错误。所以,Jenkins pipeline一般可以交付给开发使用,运维人员几乎不用操心。
4. 无服务部署
4.1 什么是无服务部署
Serverless架构是采用FaaS(函数即服务)和BaaS(后端服务)服务来解决问题的一种设计。
FaaS就是Function as a service(函数即服务)。每一个函数都是一个服务,函数可以由任何语言编写,直接托管在云平台,以服务形式运行,通过事件触发。
BaaS则是Backend as a service(后端即服务)。云平台提供的后端组件整合,开发者无需开发和维护后端服务,通过API/SDK的调用,便可获得例如数据存储、消息推送、账号管理等能力。
4.2 无服务部署的实质 4.2 无服务部署的实质
Serverless的背后,依然是虚拟机和容器。只不过,服务器部runtime安装、编译等工作,都由Serverless计算平台负责完成了。对开发人员来说,只需要维护源代码和Serverless执行环境的相关配置即可。这就叫“无服务器计算”。
4.3 无服务部署的优势
Serverless架构的最大优势,显然就是帮助用户彻底摆脱了基础设施管理这样的“杂事”,更加专注于业务开发,从而提升了效率,降低了开发和运营成本。
根据业界的统计,在商业和企业数据中心里的典型服务器,日常仅仅只提供了5%~15%的平均最大处理能力的输出。这是一种算力资源的巨大浪费。Serverless的出现,可以让用户按照实际算力使用量进行付费,属于真正的“精确计费”。
4.4 实际例子
在AWS中,运维需要把测试环境中的资源在休息日自动关闭,或在晚上关闭,以实现降本增效。这里用Lambda来取代pod的部署,可以实现用时收费,不用时免费,这是Serverless的精神所在。
以下是在aws的Lambda中,用python写下非常短小的代码
// 关闭服务器
import boto3
region = 'cn-north-1'
# Enter your instances here: ex. ['X-XXXXXXXX', 'X-XXXXXXXX']
instances = [
#nonprod-pms-bastion
'i-xxxxxexxxxxxxxxxx'
]
def lambda_handler(event, context):
ec2 = boto3.client('ec2', region_name=region)
ec2.stop_instances(InstanceIds=instances)
print('stopped your instances: ' + str(instances))
//关闭DocumentDB
import boto3
def lambda_handler(event, context):
docdb = boto3.client('docdb')
response = docdb.describe_db_clusters(DBClusterIdentifier='uat-pms-documentdb')
status = response['DBClusters'][0]['Status']
if status == 'available':
response = docdb.stop_db_cluster(DBClusterIdentifier='uat-pms-documentdb')
print('Stopped the cluster')
//关闭RDS数据库
import boto3
def lambda_handler(event, context):
rds = boto3.client('rds')
response = rds.describe_db_clusters(DBClusterIdentifier='uat-pms-aurora')
status = response['DBClusters'][0]['Status']
if status == 'available':
response = rds.stop_db_cluster(DBClusterIdentifier='uat-pms-aurora')
print('Stopped the cluster')
//工作时间开始,就可以定时或事件触发来启动RDS
import boto3
def lambda_handler(event, context):
docdb = boto3.client('docdb')
response = docdb.describe_db_clusters(DBClusterIdentifier='uat-pms-documentdb')
status = response['DBClusters'][0]['Status']
if status == 'stopped':
response = docdb.start_db_cluster(DBClusterIdentifier='uat-pms-documentdb')
print('Started the cluster')
这是调用Lambda的EventBridge,如图十四 图十四
图十四
4.5部署风险和应对
无服务部署的脚本其实就是代码,一旦跑通后,由云平台调用,指定事件或定时运行,一般不可能失败。除非在环境发生重大变化,比如依赖的服务消失了。所以,为了防止这些情况的发生,预设代码,做好报警通知尤为重要。
5.自动化部署的优势
自动化部署有巨大的优势,主要包含以下几点:
5.1 提高效率
自动化部署可以显著提高部署过程的效率。通过使用自动化工具和脚本,可以自动化执行各种部署任务,减少手动干预和人为错误。这有助于加快部署速度,减少了繁琐的手动操作和等待时间。
5.2 一致性和可靠性
自动化部署确保在不同环境和服务器之间实现一致性。通过自动执行相同的步骤和配置,可以避免人为错误和配置差异,从而提高部署的可靠性和一致性。
5.3 可重复性
自动化部署使得部署过程可重复。无论是在开发、测试还是生产环境中,都可以确保相同的部署步骤和配置被准确地应用。这样可以避免由于手动操作或环境差异而导致的问题,提高了部署的可靠性和可维护性。
5.4 可扩展性
自动化部署对于处理大规模应用程序和复杂基础架构非常有帮助。通过自动化工具和脚本,可以轻松地扩展和部署多个实例或节点,以满足高负载或增长需求。
5.5 安全性
自动化部署可以提高安全性。通过在部署过程中自动应用安全最佳实践和配置,可以减少安全漏洞和配置错误的风险。自动化还可以确保及时应用安全补丁和更新。
5.6 可追溯性和回滚能力
自动化部署可以提供可追溯性和回滚能力。通过记录部署的历史和版本控制,可以轻松追踪和管理部署的变更。如果需要回滚到先前的版本,可以自动执行回滚操作,快速恢复到稳定状态。
6. 结束语
自动化部署是运维的重要组成部分,是一种通过编写脚本和使用自动化工具来实现系统配置、应用部署和环境管理的方法。它可以提高部署的效率和一致性,减少人工操作的错误和时间成本。
通过自动化部署,运维团队可以快速、可靠地部署和更新应用程序,实现持续集成和持续交付的目标。同时,运维自动化部署还能够提供版本控制、配置管理和监控等功能,帮助团队更好地管理和维护系统。总而言之,运维自动化部署是现代化运维的重要实践,它能够提高效率、降低风险,并为企业的数字化转型提供支持。
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞6本文隶属于专栏

作者其他文章
评论 2 · 赞 10
评论 2 · 赞 4
评论 0 · 赞 10
评论 0 · 赞 5
评论 0 · 赞 8
添加新评论1 条评论
2024-04-02 10:17